前面介绍的《伙伴系统算法》用于分配大块的内存,分配的内存大小为2的n次方个连续页框,那小块内存,内核是如何分配的呢?
static struct kmem_cache *filp_cachep __read_mostly;
filp_cachep = kmem_cache_create("filp", sizeof(struct file), 0,SLAB_HWCACHE_ALIGN | SLAB_PANIC | SLAB_ACCOUNT, NULL);
struct file *f = kmem_cache_zalloc(filp_cachep, GFP_KERNEL);
上面是创建文件对象struct file的示例,调用kmem_cache_create创建一个kmem_cache类型的对象file_cachep,此file_cachep只会初始化一次。
在需要创建file对象时,调用kmem_cache_zalloc方法,所需的入参即filp_cachep。
kmem_cache_zalloc中会调用伙伴系统算法,申请2的n次方个连续的页框作为内存池,然后从池中申请一块小内存用于存放file对象数据。
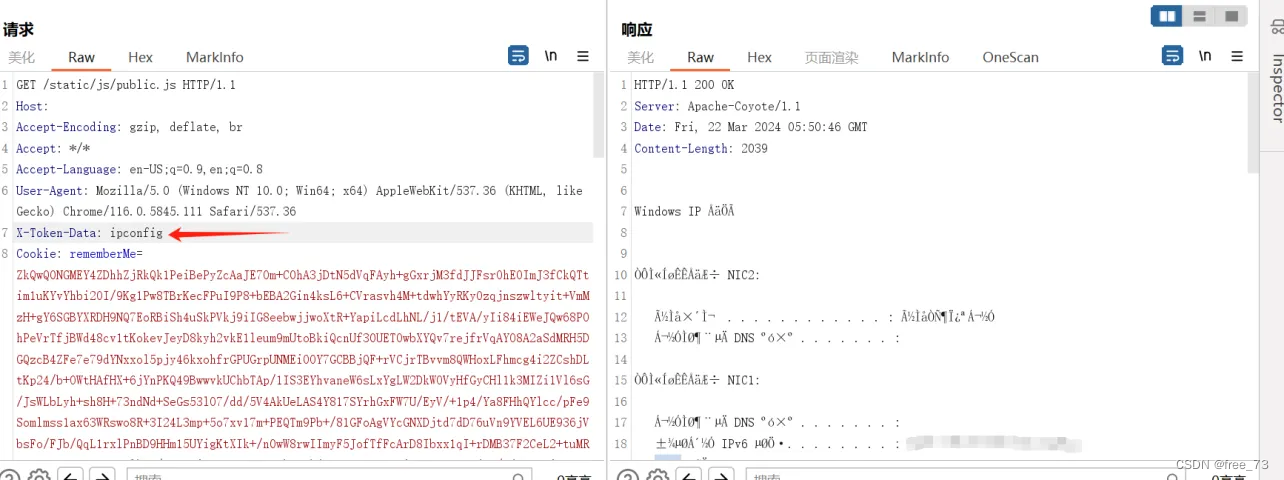
如下图,从伙伴系统申请了2个页框,然后从页框对应的内存中申请了一个file对象。
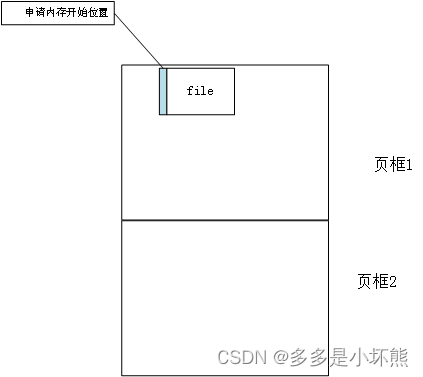
在上图的基础上,再申请一个file对象,结果如下图所示:
本文涉及到的数据结构,可以参考基本数据结构一节。
一 kmem_cache_create
kmem_cache_create用于创建kmem_cache对象,并给其某些字段赋值。kmem_cache_create返回的kmem_cache对象,最终也是调用kmem_cache_zalloc创建的,其调用路径如下:
kmem_cache_create
create_cache
kmem_cache_zalloc
所以接下来重点分析下kmem_cache_zalloc。
二 kmem_cache_zalloc
kmem_cache_zalloc
kmem_cache_alloc
slab_alloc
__do_cache_alloc
____cache_alloc
如上所示,执行核心逻辑的是____cache_alloc
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
ac = cpu_cache_get(cachep);
// 有可用的对象
if (likely(ac->avail)) {
ac->touched = 1;
objp = ac->entry[--ac->avail];
STATS_INC_ALLOCHIT(cachep);
goto out;
}
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags);
ac = cpu_cache_get(cachep);
out:
if (objp)
kmemleak_erase(&ac->entry[ac->avail]);
return objp;
}ac即 kmem_cache的cpu_cache,cpu_cache是个每cpu变量,缓存了部分待申请对象,avail记录了可申请对象的数量。如果有缓存的对象,通过ac->entry[--ac->avail]获取对象,并减少缓存数量。
如果缓存中已无对象可用,则调用cache_alloc_refill。在介绍cache_alloc_refill之前,先看下页框与kmem_cache_node的关系。
三 页框与kmem_cache_node的关系
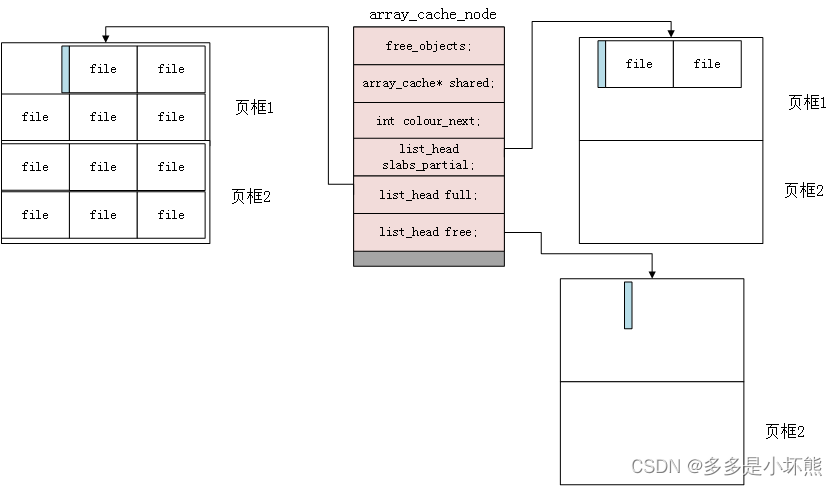
内核每次从伙伴系统中申请2的kmem_cache->gfporder次方个连续页框,申请的页框,保存到kmem_cache_node中的列表上。分三种情况:
1)页框中已经申请了部分对象,则将页框放入slabs_partial列表中;
2)页框中已无空间可用,放入slabs_full列表;
3)页框暂无分配任何对象,将页框放入slabs_free列表。
四 cache_alloc_refill
static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
{
int batchcount;
struct kmem_cache_node *n;
struct array_cache *ac, *shared;
int node;
void *list = NULL;
struct page *page;
check_irq_off();
// 跟非一致内存访问相关,对于x86i系统,此值为1
node = numa_mem_id();
// 获取每cpu高速缓存
ac = cpu_cache_get(cachep);
batchcount = ac->batchcount;
// cachep->node[node];
n = get_node(cachep, node);
BUG_ON(ac->avail > 0 || !n);
// shared为所有cpu都能访问
shared = READ_ONCE(n->shared);
// n中无缓存对象
if (!n->free_objects && (!shared || !shared->avail))
goto direct_grow;
spin_lock(&n->list_lock);
shared = READ_ONCE(n->shared);
// shared包含一些空闲对象,则用来填充ac
if (shared && transfer_objects(ac/*to*/, shared/*from*/, batchcount)) {
shared->touched = 1;
goto alloc_done;
}
while (batchcount > 0) {
/* Get slab alloc is to come from. */
// 获取一个可以分配对象的页框
page = get_first_slab(n, false);
if (!page)
goto must_grow;
check_spinlock_acquired(cachep);
batchcount = alloc_block(cachep, ac, page, batchcount);
fixup_slab_list(cachep, n, page, &list);
}
must_grow:
n->free_objects -= ac->avail;
alloc_done:
spin_unlock(&n->list_lock);
fixup_objfreelist_debug(cachep, &list);
direct_grow:
// 每cpu高速缓存中无可用对象
if (unlikely(!ac->avail)) {
// 申请页框
page = cache_grow_begin(cachep, gfp_exact_node(flags), node);
/*
* cache_grow_begin() can reenable interrupts,
* then ac could change.
*/
ac = cpu_cache_get(cachep);
if (!ac->avail && page)
// 从page获取chche对象
alloc_block(cachep, ac, page, batchcount);
cache_grow_end(cachep, page);
if (!ac->avail)
return NULL;
}
ac->touched = 1;
return ac->entry[--ac->avail];
}n->shared是所有cpu都可访问的缓存列表,如果shared列表中有可用对象,将其转移到每cpu缓存ac中,调用ac->entry[--ac->avail]获取可用对象,返回。
内核每次获取batch_count个对象放入每cpu高速缓存ac,如果未达到数量,循环调用get_first_slab(n, false),从slabs_partial列表或slabs_free列表获取页框,调用alloc_block从页框中申请对象,放入ac列表。
五 cache_grow_begin
代码执行到direct_grow,ac->avail仍然为0,说明kmem_cache_node的slabs_parital和slabs_free列表都是空的,已申请的页框空间都被用完,此时需要申请新的页框。
static struct page *cache_grow_begin(struct kmem_cache *cachep,
gfp_t flags, int nodeid)
{
void *freelist;
size_t offset;
gfp_t local_flags;
int page_node;
struct kmem_cache_node *n;
struct page *page;
local_flags = flags & (GFP_CONSTRAINT_MASK|GFP_RECLAIM_MASK);
// 申请页框
page = kmem_getpages(cachep, local_flags, nodeid);
if (!page)
goto failed;
// (page->flags >> NODES_PGSHIFT) & NODES_MASK;
page_node = page_to_nid(page);
// cachep->node[page_node];
n = get_node(cachep, page_node);
/* Get colour for the slab, and cal the next value. */
n->colour_next++;
if (n->colour_next >= cachep->colour)
n->colour_next = 0;
offset = n->colour_next;
if (offset >= cachep->colour)
offset = 0;
offset *= cachep->colour_off;
/* Get slab management. */
freelist = alloc_slabmgmt(cachep, page, offset,
local_flags & ~GFP_CONSTRAINT_MASK, page_node);
if (OFF_SLAB(cachep) && !freelist)
goto opps1;
// page->slab_cache = cachep;
// page->freelist = freelist;
slab_map_pages(cachep, page, freelist);
kasan_poison_slab(page);
cache_init_objs(cachep, page);
if (gfpflags_allow_blocking(local_flags))
local_irq_disable();
return page;
opps1:
kmem_freepages(cachep, page);
failed:
if (gfpflags_allow_blocking(local_flags))
local_irq_disable();
return NULL;
}其主要逻辑有:
1)调用kmem_getpages从伙伴系统申请2的kmem_cache->gfporder次方个连续的页框;
2)计算offset,其与缓存行有关
大体的计算方法是:第一次调用cache_grow_begin,offset为0;第二次调用cache_grow_begin,offset为sizeof(struct file);第三次调用cache_grow_begin,offset为sizeof(struct file)*2;以此类推。实际情况比这要复杂点,要考虑内存的对齐。
3)调用alloc_slabmgmt实现以下计算
设置从页框内存中开始分配对象的起始地址
void *addr = page_address(page);
page->s_mem = addr + offset;
为freelist分配内存,freelist记录了此页框中对象的分配状态。
4)调用slab_map_pages为页框的slab_cache和freelist赋值
page->slab_cache = cachep;
page->freelist = freelist;
5)返回获取的页框
cache_grow_begin执行完成后,调用alloc_block,从页框中获取对象,放入ac高速缓存。
六 alloc_block
static __always_inline int alloc_block(struct kmem_cache *cachep,
struct array_cache *ac, struct page *page, int batchcount)
{
while (page->active < cachep->num && batchcount--) {
STATS_INC_ALLOCED(cachep); // cachep->num_allocations++
STATS_INC_ACTIVE(cachep); // cachep->num_active++
STATS_SET_HIGH(cachep); // cachep->high_mark 要>= cachep->num_active
ac->entry[ac->avail++] = slab_get_obj(cachep, page);
}
return batchcount;
}
static void *slab_get_obj(struct kmem_cache *cachep, struct page *page)
{
void *objp;
// index_to_obj -> page->s_mem + cache->size * idx;
// get_free_obj -> ((freelist_idx_t *)page->freelist)[page->active];
objp = index_to_obj(cachep, page, get_free_obj(page, page->active));
page->active++;
return objp;
}ac->avail为高速缓存中可用对象的数量,每放入一个对象,avail加1;
page->active为从页框中获取的对象的数量,每获取一个,active加1;
page->freelist)[page->active]为本次循环获取的对象的地址。
下面看下freelist初始化的地方。
七 freelist初始化
static void cache_init_objs(struct kmem_cache *cachep,
struct page *page)
{
int i;
void *objp;
for (i = 0; i < cachep->num; i++) {
// page->s_mem + cachep->size * i;
objp = index_to_obj(cachep, page, i);
kasan_init_slab_obj(cachep, objp);
if (DEBUG == 0 && cachep->ctor) {
kasan_unpoison_object_data(cachep, objp);
cachep->ctor(objp);
kasan_poison_object_data(cachep, objp);
}
// ((freelist_idx_t *)(page->freelist))[i] = i;
set_free_obj(page, i, i);
}
}cache_init_objs是在cache_grow_begin中,执行完slab_map_pages后调用的。
cachep->num为此连续的页框,可以分配的对象的数量。
每次循环中,通过index_to_obj获取对象的地址,如果定义了对象的构造方法,执行其构造方法;
set_free_obj实际是将空闲对象的索引记录在了freelist中。
八 页框双向列表维护
每次申请的页框,是在cache_alloc_refill中调用cache_grow_end进行维护的。
static void cache_grow_end(struct kmem_cache *cachep, struct page *page)
{
struct kmem_cache_node *n;
void *list = NULL;
check_irq_off();
if (!page)
return;
INIT_LIST_HEAD(&page->lru);
n = get_node(cachep, page_to_nid(page));
spin_lock(&n->list_lock);
n->total_slabs++; // 申请连续页框的次数
// 页框中未分配任何对象
if (!page->active) {
// 将页框添加到slabs_free列表中
list_add_tail(&page->lru, &(n->slabs_free));
n->free_slabs++;
} else
fixup_slab_list(cachep, n, page, &list);
STATS_INC_GROWN(cachep);
n->free_objects += cachep->num - page->active;
spin_unlock(&n->list_lock);
fixup_objfreelist_debug(cachep, &list);
}
static inline void fixup_slab_list(struct kmem_cache *cachep,
struct kmem_cache_node *n, struct page *page,
void **list)
{
/* move slabp to correct slabp list: */
list_del(&page->lru);
// 页框中已无对象可分配,添加到slabs_full列表
if (page->active == cachep->num) {
list_add(&page->lru, &n->slabs_full);
if (OBJFREELIST_SLAB(cachep)) {
page->freelist = NULL;
}
} else
// 页框中已申请部分对象,还对象可用,放入slabs_partial列表
list_add(&page->lru, &n->slabs_partial);
}代码中已加注释,这里就不再赘述了。
九 返回对象地址
执行到cache_alloc_refill最后时,每cpu高速缓存列表ac中已缓存了部分对象,通过以下方法计数出返回对象的地址,并将缓存数量减1。
ac->entry[--ac->avail]
十基本数据结构
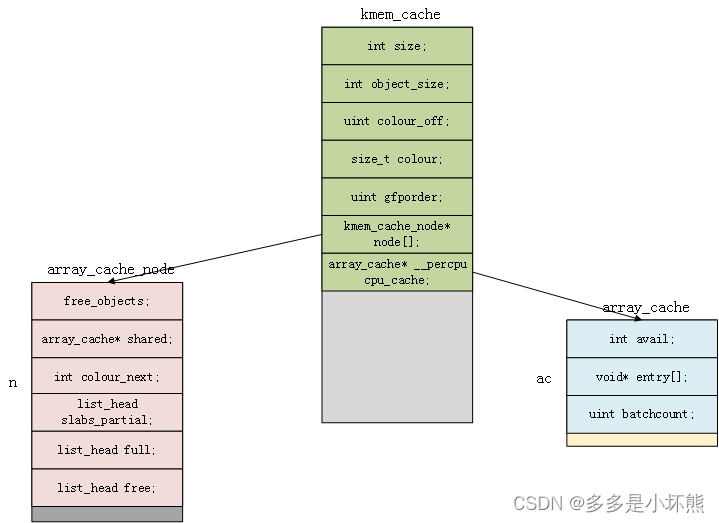
1) kmem_cache
int size; //根据kmem_cache_create入参中的size和align对齐,计算得到
int obj_size; //obj实际的大小,如:sizeof(struct file)
uint colour_off; //跟cacha_line有关
size_t colour;
uint gfporder; // kmem_cache管理的内存不够用,再申请连续页框的数量的对数
kmem_cache_node node[];
array_cache* cpu_cache; // 每cpu高速缓存,缓存了预先申请好的对象
2) kmem_cache_node
struct list_head slabs_partial; // 部分对象可分配的页框的链表
struct list_head slabs_full; // 无对象可分配的页框的链表
struct list_head slabs_free; // 未分配任何对象的页框的链表
unsigned long total_slabs; /* length of all slab lists */
unsigned long free_slabs; /* length of free slab list only */
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; //跟着色有关
struct array_cache *shared; //所有cpu都可访问的缓存列表
3) array_cache
int avail; // 可用对象的数量
void* entry[]; // 缓存了可用的对象
uint batchcount; // 如果缓存中没有可用对象,则从kmem_cache中每次获取对象的数量,获取到的对象,添加到缓存中