C/C++程序为什么比起其它语言开发的程序效率要高,一个很重要的原因就是可以直接操作内存,今天就来讲讲为什么需要内存池的技术。
从一个示例开始
先看下面两段代码,都是去重复的创建和删除对象0x5FFFFF次,他们的执行后的效率怎么样呢?
程序一:
#include <iostream>
#include <time.h>
class CTestClass{
char m_chBuf[4096];
};
int main(){
clock_t count = clock();
for(unsigned int i=0; i<0x5fffff; i++){
CTestClass *p = new CTestClass;
delete p;
}
std::cout << "Interval = " << clock() - count << " ticks" << std::endl;
return 0;
}程序二:
#include <iostream>
#include <time.h>
char buf[4100];
class CTestClass{
char m_chBuf[4096];
public:
void *operator new(size_t size){
return (void *)buf;
}
void operator delete(void *p){}
};
int main(){
clock_t count = clock();
for(unsigned int i=0; i<0x5fffff; i++){
CTestClass *p = new CTestClass;
delete p;
}
std::cout << "Interval = " << clock() - count << " ticks" << std::endl;
return 0;
}在我的机器上执行的情况是:
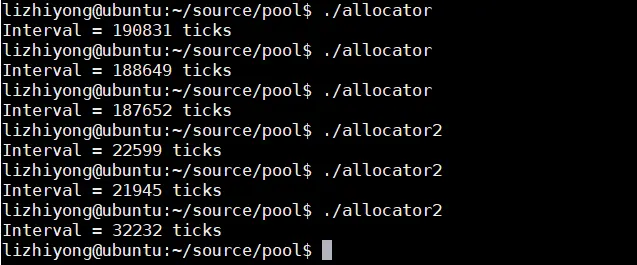
从上图的结果可以看出他们执行的效率大约相差8倍,那这是为什么呢?这是因为程序二重载了new运算后避免了使用malloc/free等系统调用,众所周知,系统调用是很耗时的操作。
内存是如何分配的
1. brk和mmap是什么鬼?
我们先看下系统内存的布局,如下图:
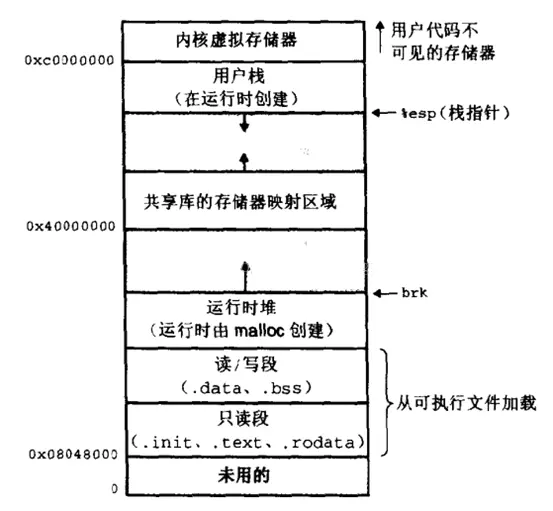
应用程序动态分配内存的区域就是用户栈和全局区直接的一块区域,这块区域允许我们使用mmap、munmap和brk去向内核申请和释放内存的系统调用,内核刚把应用程序加载时,brk指针指向全局区的高地址,当我们调用brk系统调用,内核把brk指针往高地址移动,同时内核把它所管理的这一块内存返还给用户,用户因此就获得一块可以自由操作的内存;mmap不一样的是直接从动态内存区域直接映射一块未被使用的内存块给用户,该内存块可以通过munmap释放。且看下面一段程序(程序三):
#include <unistd.h>
#include <iostream>
#include <time.h>
int main(){
void* p = sbrk(0);
clock_t count = clock();
for(unsigned int i=0; i<0x5fffff; i++){
int* p1 = (int*)p;
int ret = brk(p1 + 256); //malloc 1k
p1[256] = 256;
ret = brk(p); // free 1k
}
std::cout <<"Interval = " << clock() - count << "ticks" << std::endl;
return 0;
}sbrk和brk都可以向内核申请内存和释放,只不过调用的方式不一样而已,上面通过sbrk获得应用程序刚加载的时候brk指针所在的位置,在for循环里通过调用brk函数去申请和释放内存,但是这种通过系统调用去申请和释放内存的效率怎么样?下图是测试的结果

通过这种原始的系统调用去分配和释放内存的效率是相当低的,总体来讲存在以下三个问题:
-
brk、mmap和munmap都是系统调用,调用的成本是非常非常高的;
-
释放的时候又直接归还给操作系统了,而实际上是还可以加以利用的;
-
brk最近申请的内存没有释放的话,之前申请的内存是无法释放的,比如brk申请1K,再申请2k,再申请4k内存,此时如果想释放最先申请的1K内存,那不好意思,brk不支持这个,因为brk函数智能移动brk指针,要等到4k和2k内存都释放了才能释放这个1k内存,内存碎片的产生的根源就是因为这。
相关视频推荐
200行代码实现slab,开启内存池的内存管理(准备linux环境)
5种内存泄漏检测方式,让你重新理解内存管理
庞杂的内存问题,如何理出自己的思路出来,让你开发与面试双丰收
免费直播地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

2. glibc粉墨登场了
正是因为使用原始的系统调用brk、mmap和munmap存在很多问题,那么libc针对性的给出了优化的方案,如glibc一开始就调用brk或者mmap准备一块比较大的内存,然后把比较大的内存划分成小内存,当我们调用malloc时直接给用户,释放内存时并不一定就归还给内核,而是继续持有,以便调用malloc时能够继续用,而不用去向操作系统要(哦!我的措辞不够严谨,且听下文详细分析)。
glibc的内存块采用chunk管理,并且将大小相似的chunk用链表管理,一个链表被称为一个bin。chunk的结构如下图:
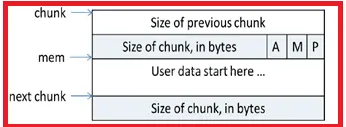
总共是128个bin,前64个bin里,相邻的bin内的chunk大小相差8字节,称为small bin,后面的是large bin,large bin里的chunk按先大小,再最近使用的顺序排列。分配内存时从所有的bins里查找最合适的chunk。如果是特别大的内存则从top chunk分配,如果不够且小于128k则调用brk扩充top chunk的内存,否则直接调用mmap分配内存。
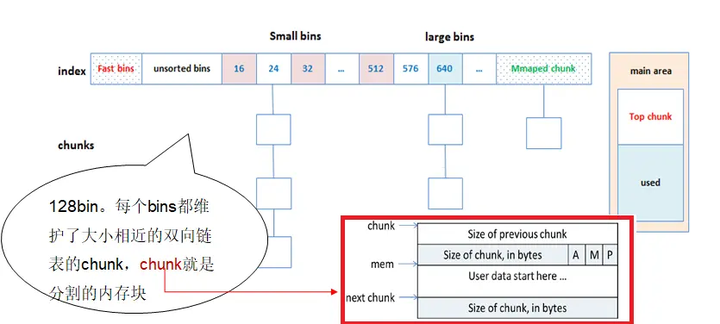
glibc的分配流程是:
-
获取分配区的锁,防止多线程冲突。
-
计算出需要分配的内存的chunk实际大小。
-
判断chunk的大小,如果小于max_fast(64b),则取fast bins上去查询是否有适合的chunk,如果有则分配结束。
-
chunk大小是否小于512B,如果是,则从small bins上去查找chunk,如果有合适的,则分配结束。
-
继续从 unsorted bins上查找。如果unsorted bins上只有一个chunk并且大于待分配的chunk,则进行切割,并且剩余的chunk继续扔回unsorted bins;如果unsorted bins上有大小和待分配chunk相等的,则返回,并从unsorted bins删除;如果unsorted bins中的某一chunk大小 属于small bins的范围,则放入small bins的头部;如果unsorted bins中的某一chunk大小 属于large bins的范围,则找到合适的位置放入。
-
从large bins中查找,找到链表头后,反向遍历此链表,直到找到第一个大小 大于待分配的chunk,然后进行切割,如果有余下的,则放入unsorted bin中去,分配则结束。
-
如果搜索fast bins和bins都没有找到合适的chunk,那么就需要操作top chunk来进行分配了(top chunk相当于分配区的剩余内存空间)。判断top chunk大小是否满足所需chunk的大小,如果是,则从top chunk中分出一块来。
-
如果top chunk也不能满足需求,则需要扩大top chunk。主分区上,如果分配的内存小于分配阀值(默认128k),则直接使用brk()分配一块内存;如果分配的内存大于分配阀值,则需要mmap来分配;非主分区上,则直接使用mmap来分配一块内存。通过mmap分配的内存,就会放入mmap chunk上,mmap chunk上的内存会直接回收给操作系统。
具体如图:
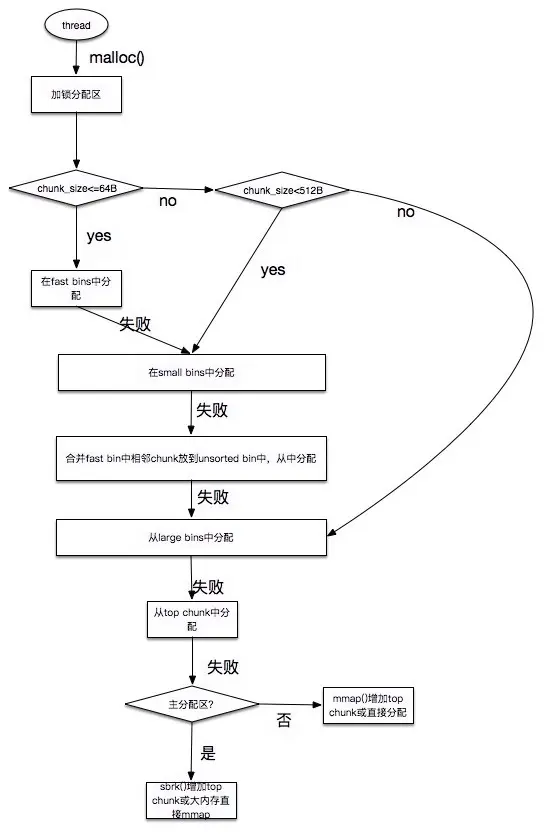
glibc的释放流程:
-
获取分配区的锁,保证线程安全。
-
如果free的是空指针,则返回,什么都不做。
-
判断当前chunk是否是mmap映射区域映射的内存,如果是,则直接munmap()释放这块内存。前面的已使用chunk的数据结构中,我们可以看到有M来标识是否是mmap映射的内存。
-
判断chunk是否与top chunk相邻,如果相邻,则直接和top chunk合并(和top chunk相邻相当于和分配区中的空闲内存块相邻)。转到步骤8
-
如果chunk的大小大于max_fast(64b),则放入unsorted bin,并且检查是否有合并,有合并情况并且和top chunk相邻,则转到步骤8;没有合并情况则free。
-
如果chunk的大小小于 max_fast(64b),则直接放入fast bin,fast bin并没有改变chunk的状态。没有合并情况,则free;有合并情况,转到步骤7
-
在fast bin,如果当前chunk的下一个chunk也是空闲的,则将这两个chunk合并,放入unsorted bin上面。合并后的大小如果大于64KB,会触发进行fast bins的合并操作,fast bins中的chunk将被遍历,并与相邻的空闲chunk进行合并,合并后的chunk会被放到unsorted bin中,fast bin会变为空。合并后的chunk和topchunk相邻,则会合并到topchunk中。转到步骤8
-
判断top chunk的大小是否大于mmap收缩阈值(默认为128KB),如果是的话,对于主分配区,则会试图归还top chunk中的一部分给操作系统。free结束。
那么glibc存在什么不足呢?
-
后分配的内存先释放,因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
-
多线程锁开销大, 需要避免多线程频繁分配释放。
-
内存从thread的分配区中分配, 内存不能从一个分配区移动到另一个分配区, 就是说如果多线程使用内存不均衡,容易导致内存的浪费。比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena,但是线程1的300M却不能用了。
-
每个chunk至少8字节的开销很大
-
不定期分配长生命周期的内存容易造成内存碎片,不利于回收。 64位系统最好分配32M以上内存,这是使用mmap的阈值。
3. 是时候请出tamalloc了
tcmalloc是Google开源的一个内存管理库, 作为glibc malloc的替代品。目前已经在chrome、safari等知名软件中运用。
Talk is cheap, show me the code。
#include <iostream>
#include <time.h>
#include <google/tcmalloc.h>
class CTestClass{
char m_chBuf[4096];
};
int main(){
clock_t count = clock();
for(unsigned int i=0; i<0x5fffff; i++){
CTestClass *p = new CTestClass;
delete p;
}
std::cout << "Interval = " << clock() - count << " sec" << std::endl;
return 0;
}同样的代码引入了tcmalloc分配内存后,效率怎么样呢?
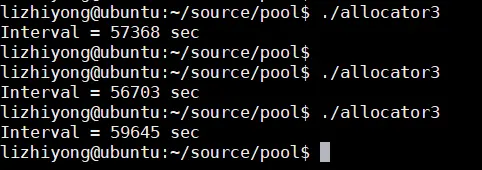
至此,我们做个总结:

那tcmalloc又是如何做到的呢?
4.tcmalloc解决并发和内存碎片问题
我们先来看一张图:
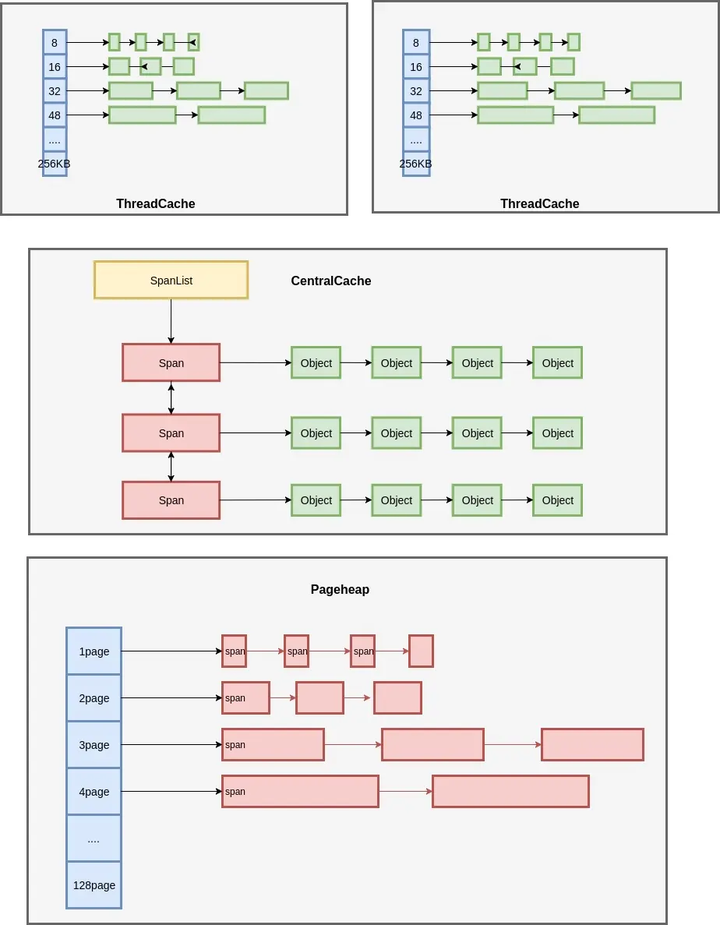
我们先来解释一下,tcmalloc为每一个线程分配了一个ThreadCache区域,每个线程都从属于自己的ThreadCache里分配和释放内存,这样就避免了glibc里多线程分配和释放内存的时候的锁的操作,锁是很有代价的,从上文的对比测试我们也能查看出他们的差异,那么我们总结出今天的第一个设计上的结论:真正高效的并发不是使用互斥锁、原子操作和自旋锁去解决对共享资源的访问,而是不共享任何资源,如果真要共享那么实现线程/进程间的通信。
那么tcmalloc是如何优化内存碎片的问题呢?答案就是CentralCache,当释放内存的时候,ThreadCache依然遵循批量释放的策略,对象积累到一定程度就释放给 CentralCache;CentralCache发现一个 Span的内存完全释放了,就可以把这个 Span 归还给 PageHeap;PageHeap发现一批连续的Page都释放了,就可以归还给操作系统,当ThreadCache的内存不够用的时候,那么就向CentralCache去借内存,然后分配出去,那么我们就能得出一个结论内存可以通过CentralCache在ThreadCache间流动,那么就在glibc的再一次优化了内存利用率,降低了内存碎片率。
高性能服务器为什么需要内存池
最后我们以一位大师的话来总结为什么需要内存池的设计:

为什么需要内存池