前言:相信通过前面的虚拟文件系统VFS及一个具体的Ext2文件系统博文,大家对基本的VFS体系有一个大致的掌握了吧。从本章开始,我们将讨论一些VFS底层的技术细节,磁盘高速缓存就是其中一个重要的技术。磁盘高速缓存是一种软件机制,它允许系统把通常存放在磁盘上的一些数据保留在RAM中,以便对那些数据的进一步访问而不用再访问磁盘。
因为对同一磁盘数据的反复访问频繁发生,所以磁盘高速缓存对系统性能至关重要。与磁盘交互的用户进程有权反复请求读或写同一磁盘数据。此外,不同的进程可能也需要在不同的时间访问相同的磁盘数据。例如,你可以使用cp命令拷贝一个文本文件,然后调用你喜欢的编辑器修改它。为了满足你的请求,命令shell将创建两个不同的进程,它们在不同的时间访问同一个文件。
我们曾在前面的博文中提到过其他的磁盘高速缓存:目录项高速缓存和索引节点高速缓存,前者存放的是描述文件系统路径名的目录项对象,而后者存放的是描述磁盘索引节点的索引节点对象。不过要注意,目录项对象和索引结节点对象不只是存放一些磁盘块内容的缓冲区,而是还加了一些内核感兴趣的其他信息,这些内容并不是从磁盘的某一个块上读取出来的;由此而知,目录项高速缓存和索引节点高速缓存是特殊的磁盘高速缓存,但不是属于我们这里讲的磁盘高速缓存概念的范围。
我们这里介绍的磁盘高速缓存其实是磁盘高速缓存——一种对完整的数据页进行操作的磁盘高速缓存,下面我们就从这个概念开始入手:
1,页高速缓存
页高速缓存(page cache)是Linux内核所使用的主要磁盘高速缓存。在绝大多数情况下,内核在读写磁盘时都会引用页面高速缓存。新页被追加到页高速缓存以满足用户态进程的读写请求。如果页不在高速缓存中,新页就被加到高速缓存中,然后用从磁盘读出的数据填充它。如果内存有足够的空闲空间,就让该页在高速缓存中长期保留,使其他进程在使用该页时不再访问磁盘。
同样,在把一页数据写到块设备之前,内核首先检查对应的页是否已经在高速缓存中;如果不在,就要先在其中增加一个新项,并用要写到磁盘中的数据填充该项。I/O数据的传送并不是马上开始,而是要延迟几秒之后才对磁盘进行更新,从而使进程有机会对要写入磁盘的数据做进一步的修改(换句话说,就是内核执行延迟的写操作)。
内核的代码和内核数据结构不必从磁盘读,也不必写入磁盘(如果要在关机后恢复系统的所有状态——其实几乎不会出现这种情况,可以执行“挂起到磁盘”操作(hibernation),RAM的全部内容保存到交换区,时此我们不做更多的讨论。),因此,在高速缓存中的也面可能是下面的类型:
含有普通文件数据的页面。我们会在后面的博文描述内核如何处理它们的读、写和内存映射操作。
含有目录的页。其实,Linux采用与普通文件类似的方式操作目录文件。
含有直接从块设备文件(跳过文件系统层)读出的数据的页。内核处理这种页与处理含有普通文件的页使用相同的函数集合。
含有用户态进程数据的页面,但页中的数据已经被交换到磁盘。内核可能会强行在页高速缓存中保留一些页面,而这些页面中的数据已经被写到交换区(可能是普通文件或磁盘分区)。
-属于特殊文件系统文件的页,如共享内存的进程间通信(Interprocess Communication, IPC)所使用的特殊文件系统shm。
从上面我们可以得出结论,页高速缓存中的每个页所包含的数据肯定属于某个文件。这个文件(或者更准确地说是文件的索引节点)就称为页的所有者(owner)。(即使含有换出数据的页面都属于同一个所有者,即使它们涉及不同的交换区。)
几乎所有的文件读写和写操作都依赖于页面的高速缓存。只有在O_DIRECT标志被置位而进程打开文件的情况下才会出现例外:此时,I/O数据的传送绕过了页高速缓而使用了进程用户态地址空间的缓冲区;少数数据库应用软件为了能采用自己的磁盘高速缓存算法而使用了O_DIRECT标志。
页面高速缓存中的信息单位显然是一个完整的数据页。一个页中包含的磁盘块在物理上不一定是相邻的,所以不能用设备号和块号来识别它,取而代之的是,通过页的所有者和所有者数据中的索引(通常是一个索引节点和在相应文件中的偏移量)来识别页高速缓存中的页。
2,address_space对象
页高速缓存的核心数据结构是address_space对象,它是一个嵌入在页所有者的索引节点对象中的数据结构(页被换出可能会引起缺页异常,这些被换出的页拥有不在任何索引节点中的公共address_space对象)。高速缓存中的许多页可能属于同一个所有者,从而可能被链接到同一个address_space对象。该对象还在所有者的页面和对这些页面的操作之间建立起链接关系。
每个页描述符都包括两个字段mapping和index,把页链接到页高速缓存的。mapping字段指向拥有页的索引节点的address_space对象,index字段表示在所有者的地址空间中以页大小为单位的偏移量,也就是在所有者的磁盘映像中页中数据的位置。在页面高速缓存中查找页面时使用这两个字段。
值得庆幸的是,页面高速缓存可以包含同一磁盘数据的多个副本。例如,可以用下述方式访问普通文件的同一4KB的数据块:
读文件;因此,数据就包含在普通文件的索引节点所拥有的页面中。
从文件所在的设备文件(磁盘分区)读取块。因此,数据就包含在块设备文件的主索引节点所拥有的页中。
资料直通车:最新Linux内核源码资料文档+视频资料
内核学习地址:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
因此,两个不同address_space对象所引用的两个不同的页中出现了相同的磁盘数据。address_space对象包含如下所示:
struct address_space {
struct inode *host; /* 指向拥有该对象的索引节点的指针(如果存在) */
struct radix_tree_root page_tree; /* 表示拥有者页的基树(radix tree)的根 */
rwlock_t tree_lock; /* 保护基树的自旋锁 */
unsigned int i_mmap_writable;/* 地址空间中共享内存映射的个数 */
struct prio_tree_root i_mmap; /* radix优先搜索树的根 */
struct list_head i_mmap_nonlinear;/* 地址空间中非线性内存区的链表 */
spinlock_t i_mmap_lock; /* 保护radix优先搜索树的自旋锁 */
unsigned int truncate_count; /* 截断文件时使用的顺序计数器 */
unsigned long nrpages; /* 所有者的页总数 */
pgoff_t writeback_index;/* 最后一次回写操作所作用的页的索引 */
const struct address_space_operations *a_ops; /* 对所有者页进行操作的方法 */
unsigned long flags; /* 错误位和内存分配器的标志 */
struct backing_dev_info *backing_dev_info; /* 指向拥有所有者数据的块设备的backing_dev_info的指针 */
spinlock_t private_lock; /* 通常是管理private_list链表时使用的自旋锁 */
struct list_head private_list; /* 通常是与索引节点相关的间接块的脏缓冲区的链表*/
struct address_space *assoc_mapping; /* 通常是指向间接块所在块设备的address_space对象的指针 */
} __attribute__((aligned(sizeof(long))));如果页高速缓存中页的所有者是一个文件,address_space对象就嵌入在VFS索引节点对象的i_data字段中。索引节点的i_mapping字段总是指向索引节点的数据页所有者的address_space对象。address_space对象的host字段指向其所有者的索引节点对象。
因此,如果页属于一个文件(存放在Ext3文件系统中),那么页的所有者就是文件的索引节点,而且相应的address_space对象存放在VFS索引节点对象的i_data字段中。索引节点的i_mapping字段指向同一个索引节点的i_data字段,而address_space对象的host字段也指向这个索引节点。
不过,有些时候情况会更复杂。如果页中包含的数据来自块设备文件,即页含有存放着块设备的“原始”数据,那么就把address_space对象嵌入到与该块设备相关的特殊文件系统bdev中文件的“主”索引节点中(块设备描述符的bd_inode字段引用这个索引节点,参见“块设备”博文)。因此,块设备文件对应索引节点的i_mapping字段指向主索引节点中的address_space对象。相应地,address_space对象的host字段指向主索引节点。这样,从块设备读取数据的所有页具有相同的address_space对象,即使这些数据位于不同地块设备文件。
i_mmap, i_mmap_writable, i_mmap_nonlinear和i_mmap_lock字段涉及内存映射和反映射,我们将在后面的博文讨论这些主题。
backing_dev_info字段指向backing_dev_info描述符,后者是对所有者的数据所在块设备进行有关描述的数据结构。
private_list字段是普通链表的首部,文件系统在实现其特定功能时可以随意使用。例如,Ext2文件系统利用这个链表收集与索引节点相关的“间接”块的脏缓冲区。当刷新操作把索引节点强行写入磁盘时,内核也同时刷新该链表中的所有缓冲区。此外,Ext2文件系统在assoc_mapping字段中存放指向间接块所在块设备的address_space对象,并使用assoc_mapping->private_lock自旋锁保护多处理器系统中的间接块链表。
address_space对象的关键字段是a_ops,它指向一个类型为address_space_operations的表,表中定义了对所有者的页进行处理的各种方法:
struct address_space_operations {
/* 写操作(从页写到所有者的磁盘映像) */
int (*writepage)(struct page *page, struct writeback_control *wbc);
/* 读操作(从所有者的磁盘映像读到页) */
int (*readpage)(struct file *, struct page *);
/* 如果对所有者页进行的操作已准备好,则立刻开始I/O数据的传输 */
void (*sync_page)(struct page *);
/* Write back some dirty pages from this mapping. */
/* 把指定数量的所有者脏页写回磁盘 */
int (*writepages)(struct address_space *, struct writeback_control *);
/* Set a page dirty. Return true if this dirtied it */
/* 把所有者的页设置为脏页 */
int (*set_page_dirty)(struct page *page);
/* 从磁盘中读所有者页的链表 */
int (*readpages)(struct file *filp, struct address_space *mapping,
struct list_head *pages, unsigned nr_pages);
/*
* ext3 requires that a successful prepare_write() call be followed
* by a commit_write() call - they must be balanced
*/
/* 为写操作做准备(由磁盘文件系统使用) */
int (*prepare_write)(struct file *, struct page *, unsigned, unsigned);
/* 完成写操作(由磁盘文件系统使用) */
int (*commit_write)(struct file *, struct page *, unsigned, unsigned);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
/* 从文件块索引中获取逻辑块号 */
sector_t (*bmap)(struct address_space *, sector_t);
/* 使所有者的页无效(截断文件时使用) */
void (*invalidatepage) (struct page *, unsigned long);
/* 由日志文件系统使用以准备释放页 */
int (*releasepage) (struct page *, gfp_t);
/* 所有者页的直接I/O传输(绕过页高速缓存) */
ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov,
loff_t offset, unsigned long nr_segs);
struct page* (*get_xip_page)(struct address_space *, sector_t,
int);
/* migrate the contents of a page to the specified target */
int (*migratepage) (struct address_space *,
struct page *, struct page *);
};其中最重要的方法是readpage, writepage, prepare_write和commit_write。我们将在后面的博文对它们进行讨论。在绝大多数情况下,这些方法把所有者的索引节点对象和访问物理设备的低级驱动程序联系起来。例如,为普通文件的索引节点实现readpage方法的函数知道如何确定文件页的对应块在物理磁盘设备上的位置。
3,基树
Linux支持大到几个TB的文件。访问大文件时,页面高速缓存中可能充满太多的文件页,以至于顺序扫描这些页要消耗大量的时间。为了实现页高速缓存的高效查找,Linux2.6采用了大量的搜索树,其中每个address_space对象对应一棵搜索树。
address_space对象的page_tree字段是基数(radix tree)的根,它包含指向所有者的描述符的指针。通过它,内核能够通过快速搜索操作来确定所需要的页是否在高速缓存中。当查找所需要的页时,内核把页索(page->index)引转换为基数中的路径,并快速找到页描述符所(或应当)在的位置。如果找到,内核可以从基树获得页描述符,而且还可以很快确定所找到的页是否是脏页(也就是应当被刷新到磁盘的页),以及其数据的I/O传送是否正在进行。
基树的每个节点可以有多到64个指针指向其他节点或页描述符。底层节点存放指向页描述符的指针(叶子节点),而上层的节点存放指向其他节点(孩子节点)的指针。每个节点由radix_tree_node数据结构表示,它包括三个字段:slots是包括64个指针数组,count是记录节点中非空指针数量的计数器,tags是二维的标志数组:
struct radix_tree_node {
unsigned int count;
void *slots[RADIX_TREE_MAP_SIZE];
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};
#define RADIX_TREE_MAP_SIZE (1UL << RADIX_TREE_MAP_SHIFT) /* 64 */
#define RADIX_TREE_MAP_SHIFT 3树根由radix_tree_root数据结构表示,他有三个字段:height表示树的当前深度(不包括叶子节点的层数),gfp_mask指定为新节点请求内存时所用的标志,mode指向与树中第一层节点相应的数据结构radix_tree_node(如果有的话):
struct radix_tree_root {
unsigned int height;
gfp_t gfp_mask;
struct radix_tree_node *rnode;
};我们来看一个简单的例子。如果树中的索引都小于63,那么树的深度就等于1,因为可能存在的64个叶子可以都存放在第一层的节点中[如图(a)所示]。不过,如果与索引131相应的新页的描述符肯定存放在页高速缓存中,那么树的深度就增加为2,这样基树就可以查找多达4095个索引[如图(b)所示]。
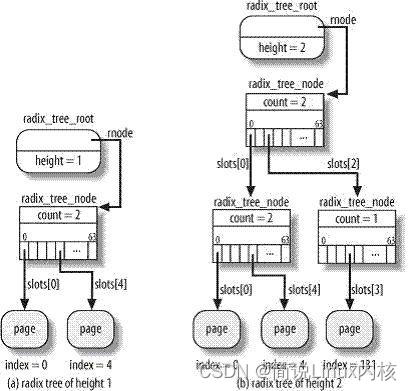
回顾一下分页系统是如何利用页表实现线性地址到物理地址转换的,从而理解如何实现页表查找。线性地址最高20位分成两个10位的字段:第一个字段是页目录中的偏移量,而第二个字段是某个页目录项所指向的页表中的偏移量。
技术中使用类似的方法。页索引相当于线性地址,不过页索引中要考虑的字段的数量依赖于基数的深度。如果基数的深度为1,就只能表示从0~63范围的索引,因此页索引得第6位被解释为slots数组的下标,每个下标对应第一层的一个节点。如果基数的深度为2,就可以表示从0~4095范围的索引,页索引得第12位分成两个6位的字段,高位的字段用于表示第一层节点数组的下标,而低位的字段用于表示第二层数组的下标。依此类推,如果深度等于6,页索引得最高两位(因为page->index是32位的)表示第一层节点数组的下标,接下来的6位表示第二层节点数组的下标,这样一直到最低6位,它们表示第六层节点数组的下标。
如果基树的最大索引小于应该增加的页的索引,那么内核相应地增加树的深度;基树的中间节点依赖于索引得值。


![[ 云计算 | Azure ] Chapter 04 | 核心体系结构之数据中心、区域与区域对、可用区和地理区域](https://img-blog.csdnimg.cn/1e5099759bb842a29a65cd91cb3b4305.png)